Кэш-память процессора
Автор: AmeliePick.
Дата публикации: 6 марта 2026 г.
Предисловие
Данная статья является обзорно-технической и объясняет схемотехнику, структуры, алгоритмы и политики работы кэш-памяти, с указанием деталей реализаций архитектур и микроархитектур процессоров Intel(и частично AMD), начиная с поколения Nehalem(2008) по Rocket Lake-S(2021). Все рассматриваемые примеры архитектур процессоров базируются на x86-64, если не указано иное. Данный материал может быть началом углублённого изучения архитектур и устройства процессоров и предполагается, что читатель базово знаком с архитектурой и/или устройством современных систем. Также, в этой статье не рассматриваются/опускаются детали реализации других частей процессора, как например конвейера исполнения, так или иначе связанных с кэшем: если указывается, что конвейер остановлен, читатель волен интерпретировать это в зависимости от своего знания(или не) и понимания устройства исполнения инструкций.
Некоторые понятия, как например, структура кэш-линии – являются чисто абстрактными, т.к. в действительности могут иметь разную структуру в зависимости от конкретной архитектуры.
Микро/архитектуры в этой статье рассматриваются с точки зрения монолитного кристалла, если не указано иное.
Введение
Из-за физической особенности реализации оперативной памяти, она имеет большие задержки. Каждое обращение к ней сказывается в виде простоев конвейера процессора и, как следствие, возникает падение производительности исполняемого кода. По этой причине, в процессоры была добавлена память небольшого объёма, именуемая кэшем, которая хранит копии часто используемых данных из основной памяти, часто предотвращая медленные запросы к ней, длящиеся сотни тактов процессора. Кэш память имеет другую схемотехнику, которая позволяет иметь очень малые задержки и способна работать на частоте ядер.
Для того, чтобы понять, почему любой запрос в оперативную память от процессора является очень долгим, требуется разобраться в её устройстве и устройстве самой кэш-памяти.
1. Устройство памяти
1.1 Динамическая память
Примечание: Существует два способа реализации динамической памяти: DRAM и SDRAM. Именно память SDRAM рассматривается в этой статье.
В динамической ОЗУ каждый бит информации представляется как заряд конденсатора. Такие ячейки располагаются в виде матриц, внутри чипов памяти и разделяются на несколько банков, для эффективной параллельной работы.
Любой конденсатор имеет ток утечки – это значит, что хранимый бит, если он представлял логическую 1, скоро превратится в логический 0, что не может гарантировать целостность памяти. Поэтому, их необходимо раз в период регенерировать – это значение указывается обычно таймингом tREFI(Refresh Interval) и сообщает через сколько тактов шины памяти необходимо начать регенерацию конденсаторов. В рамках этой статьи мы не станем углубляться в механизмы и логики работы самой оперативной памяти, а поверхностно затронем некоторые её аспекты. Однако, стоит отметить, что данный тайминг напрямую привязан к температуре чипов памяти. Так как чем больше температура, тем сильнее ток утечки. И несмотря на то, что данный параметр обычно указывается в тактах шины, он имеет связь со временем. Так, в большинстве памяти стандарта DDR4, DDR5, это значение равно 7.8 микросекундам. Это значит, что при повышении частоты памяти и увеличении нагрева, этот тайминг должен тоже корректироваться, сохраняя 7.8 мкс, либо уменьшая его из-за возросшей температуры. Так, для перевода тактов в микросекунды можно использовать формулу:
Для перевода в наносекунды, очевидно:
После того, как известно время, через которое необходимо восстанавливать заряд, необходимо и знать время, которое будет потрачено на саму регенерацию – это тайминг tRFC(Refresh Cycle Time) и он сообщает, сколько тактов шины требуется на то, чтобы часть конденсаторов в чипах памяти была регенерирована для одной команды REF(контроллер памяти обновляет заряд не сразу для всей матрицы, а лишь для нескольких строк в каждом банке матрицы в каждом чипе одного ранга). Именно tRFC определяет время, в течении которого обращение к памяти не может быть выполнено. Разумеется, чем он ниже, тем быстрее контроллер получит доступ. Однако, данный тайминг также сильно привязан к физическим характеристикам чипа памяти. Слишком низкое значение может привести к тому, что все регенерируемые конденсаторы не зарядятся до необходимого уровня и могут потерять свой заряд быстрее, что приведёт к искажению данных.
К следующим факторам медленной работы памяти, относятся процессы получения доступа к данным. Так как вся память представляет из себя матрицу ячеек, то контроллеру памяти необходимо:
1. Открыть строку(англ. wordline). После открытия строки, данные из ячейки(не одной, а сразу всех ячеек в строке) поступают на столбец(а точнее столбцы каждой ячейки в строке) (англ. bitline – BL), откуда далее перемещаются на усилитель сигнала(англ. sense amplifier). В дополнение к BL, добавляется вторая битлиния /BL, которая является инверсной. Такая схема создаёт дифференциальную пару(подробнее это описано в начале раздела 1.2). Заряд с BL достигает усилителя сигнала, который по полярности разности потенциалов между /BL и BL определяет хранила ли ячейка логическую 1 или 0. После определения сигнала, опорная и целевая битлинии меняют своё напряжение к нужному логическому уровню. Если бит 1, то /Bl = 0(Ground), BL = Vdd. Если бит 0 – то /Bl = Vdd, Bl = 0. Так как факт чтения ячейки разряжает конденсатор, то этот этап позволяет зарядить его и пока строка открыта, отдельная часть схемы усилителя сигнала заряжает конденсатор(см. п 3). Сам усилитель сигнала выступает в роли буфера на время цикла доступа к ячейке памяти. Заряд бита здесь хранится в бистабильной схеме. Время, которое будет затрачено с момента открытия строки и получения бита в усилителе, готовым для дальнейших операций, представлено таймингом tRCD.
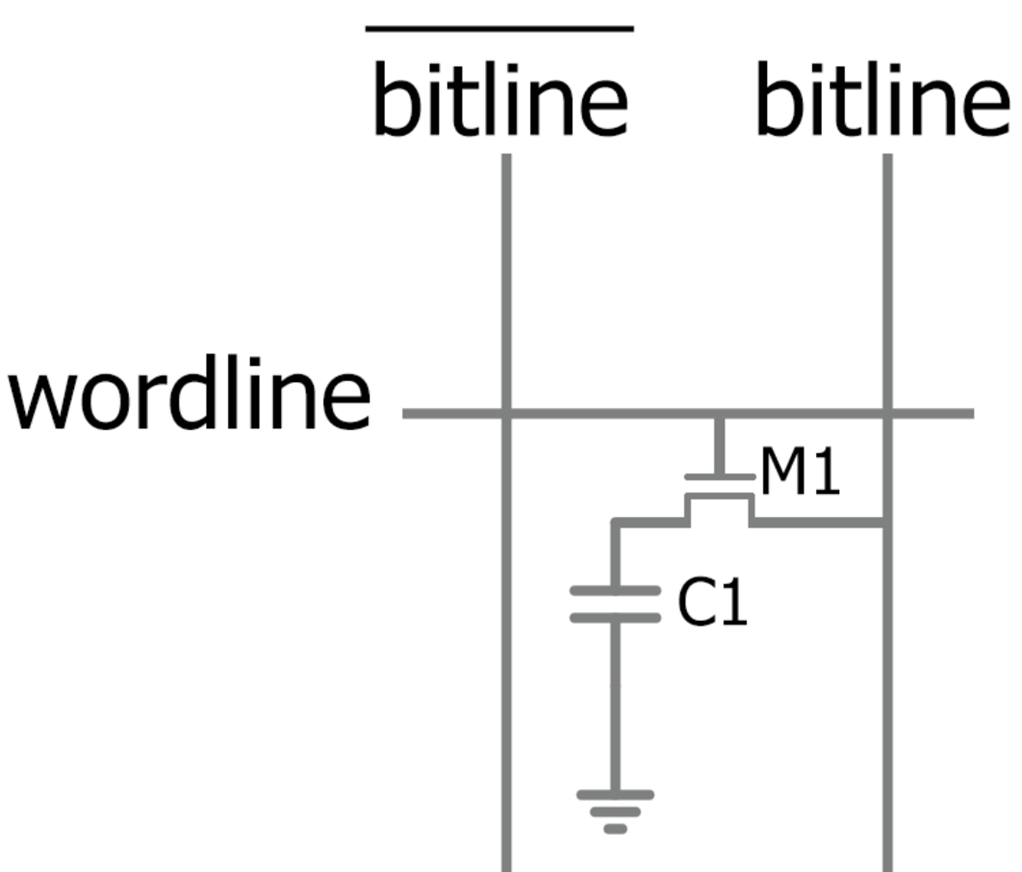
2. Получить бит из нужного столбца(англ. bitline). На данном этапе, этот бит будет находится уже в буфере. Время, которое будет затрачено на поиск бита в буфере и постановкой его на шину данных, представлено таймингом CL. Отсюда следует, что любой доступ к данным, с уже открытой строки, будет как минимум равен тактам CL. Для получения первого бита в ещё закрытой строке, при первом обращении к памяти, будет затрачено времени: tRCD + CL.
3. Строка остаётся открытой, если того требуется от контроллера, например, если доступ к этим данным всё ещё необходим. Или, строка остаётся открытой, на протяжении тайминга tRAS, но не более tRAS-max из-за физического влияния на соседние ячейки. В течении времени tRAS, конденсатор в ячейке будет заряжен, пока сам бит находится в усилителе.
4. В конце чтения ячейки, надо закрыть строку и подготовить битлинии. На данном этапе, контроллер учтёт время открытия строки и tRAS. И либо начнёт закрытие, либо сперва выждет tRAS. Закрытие осуществляется так, что контроллер снимает сигнал с wordline и далее подаётся команда precharge. Она необходима, чтобы напряжение на битлиниях вновь стало нейтральным. Ведь пока в усилителе хранится бит ячейки, напряжение битлиний связано с его логическим значением(см. п. 1). После того, как напряжение битлиний достигло нейтрального(обычно Vdd / 2), операция закрытия считается завершённой. Время, между моментом начала закрытия строки и получения нейтрального состояния на линиях, представлено таймингом tRP. После истечения времени tRP, контроллер может начать открывать другую строку в текущем банке памяти.
Описанные алгоритмы работы памяти уже создадут приличную задержку, равную примерно десятку наносекунд. Также к этому добавляются задержки логики в самом контроллере памяти(который является частью процессора и называется IMC) плюс задержки шины по передаче сигнала от сокета к чипам памяти. Однако, для сглаживания этих базовых задержек применяются: пакетный режим(англ. Burst Mode) и удвоенная частота(DDR).
Пакетный режим – позволяет одной командой прочитать сразу целый блок данных из памяти, тем самым не забивая шину управления излишним количеством одной и той же команды. А также снижает количество простоев контроллера, так как данные из памяти не ждут команды, а отправляются по очереди, сразу по тактовому сигналу шины.
Удвоенная частота(англ. Double Data Rate, DDR) – отправка данных происходит дважды за один такт. Сначала на фронте сигнала с шины, затем на срезе/спаде.
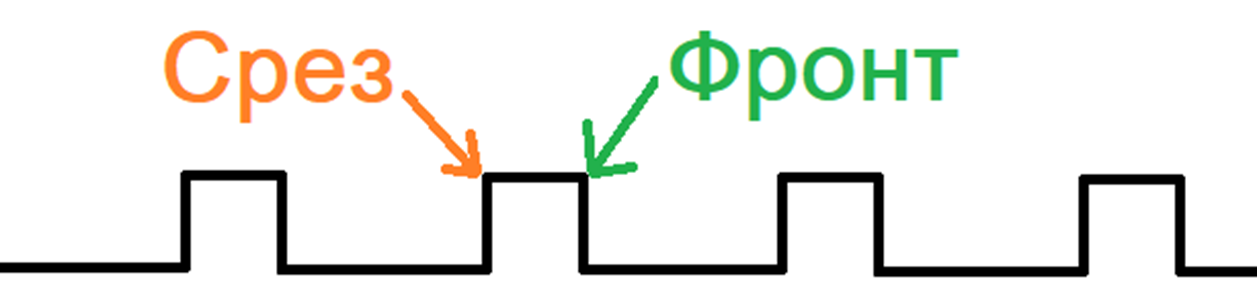
DDR буквально в два раза повышает пропускную способность памяти, по сравнению с SDR(англ. Single Data Rate). При этом стоит понимать, что частота шины памяти, может быть в два раза ниже, и в контексте DDR правильно было бы указывать не эффективную частоту в МГц, а кол-во транзакций за один такт шины. То есть, если DDR имеет эффективную частоту 1600 МГц, это означает, что она способна отправить/получить 1600 мегатранзакций, на частоте шины в 800 МГц. А вот отправка команд на слоты ОЗУ, может иметь скорость самой шины управления(У DDR5 стандарта, шина управления и адреса также может отправлять данные дважды за такт).
В начале главы было упомянуто два типа памяти: DRAM и SDRAM. Их основное отличие состоит в том, что DRAM является асинхронной и получает/отправляет данные не по тактам шины, а по готовности. SDRAM(англ. Synchronous DRAM) же является развитием DRAM и работает с частотой шины, давая возможность контроллеру выстраивать очереди запросов, тем самым ускоряя саму работу.
Например, при DRAM контроллер ждёт 40 нс, жёстко прописанные в его логике, ожидая данные из памяти. При использовании SDRAM, каждый такт шины продвигает условный сигнал по цепочке триггеров внутри микросхемы памяти, что превращает такую память в конвейер. Но некоторые этапы сдвига сигнала требуют времени из-за задержек распространения сигнала и физического срабатывания компонентов – это регулируется таймингами. То есть, если читается строка X, то на такте 1 выполняется команда A, она сама по себе занимает время, равное 3 тактам – контроллер ждёт 3 такта и на 4 такте посылает команду Б. При этом, контроллер может в момент ожидания послать и другую команду, но уже на другую строку(в другом банке). Тайминги регулируют не только время готовности сигнала, но и позволяют контроллеру планировать и создавать очередь команд, которые не исказят данные с одной строки, но могут одновременно работать с несколькими строками.
1.2 Статическая память
SRAM, она же Static Random-Access Memory. Статичная потому, что в ней нет необходимости регенерации хранимых данных. Данные хранятся в бистабильной схеме, состоящей обычно из 6 транзисторов, хотя существуют и другие разновидности.
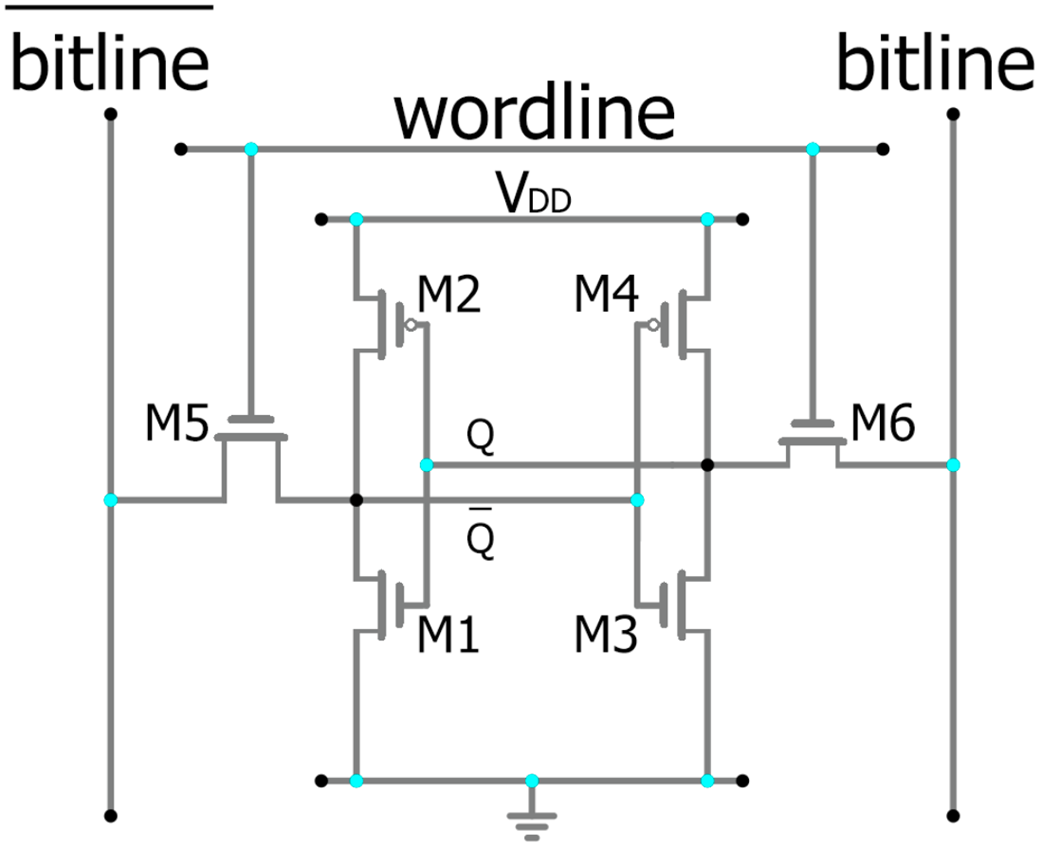
Здесь тоже имеется строка(wordline), и две битлинии. Как и в динамической памяти, это связано с тем, что сами битлинии являются довольно длинными, имеют множество подключений к другим ячейкам в матрице, а равно и к их электронным компонентам. Такая организация увеличивает паразитную ёмкость, которая способна замедлить и исказить сигнал. Также длины битлиний хватит для превращения их в антенну, что способно наводить шум и помехи. В случае дифференциальной пары, считывается всего лишь разница потенциалов и её полярность, что делает такую схему устойчивой к шумам, а также позволяет определять даже небольшие изменения(в десятки милливольт). В динамической памяти, до и во время выбора битлиний(см. п 1, г. 1), они должны быть заряжены одинаково на определённый уровень так, что при изменении целевой битлинии её можно было с чем-то сравнить(/BL). Усилитель сигнала сравнит опорную(/BL) битлинию с целевой(BL) и сможет уловить разницу. SRAM тоже использует диф. пару, а также предзаряд битлиний. Как и в DRAM, это необходимо для работы самой диф. пары. Различия только в уровне напряжения. Если для DRAM это обычно Vdd / 2, то для SRAM это Vdd(на практике это будет зависеть от архитектуры самой памяти). Не углубляясь в схемотехнику SRAM и особенности транзисторов, такой уровень необходим для стабильности самой ячейки. Сохраняя на битлинии напряжение, равное заряду внутри ячейки для логической 1(Vdd) как минимум гарантируется, что из-за малых размеров транзистора и поэтому наличия большего тока утечки, напряжение в ячейке не будет меняться, утекая на битлинию с низким потенциалом. В случае же, если битлиния будет иметь меньший потенциал, чем узел ячейки, то при попытке её чтения и открытии транзистора, напряжение в ней может кратковременно упасть ниже порога переключения внутренних транзисторов, что приведёт к инверсии хранимого значения. В обратном направлении это тоже справедливо и в некоторой литературе описывается термином Read disturb.
Всё это делает процесс считывания диф. пары отличным от DRAM. Так, если в ячейке хранится логическая единица, то на линию BL поступит Vdd, при этом BL уже предзаряжена на это значение – то есть изменения напряжения на BL не произойдёт. Однако, в другой половине, ячейка хранит 0(Ground) уровень напряжения, и при подключении /BL к ячейке, напряжение на этой линии начнёт проседать. Что определится усилителем сигнала как логическая 1. При логическом нуле, процесс ровно обратный: и просядет уже линия BL. Как только одна из линий начинает проседать к «земле», усилитель довольно быстро это определяет, защёлкивается, сигнал с wordline снимается, а битлинии уходят на дозарядку. Обычно, данный процесс в SRAM, и тем более в кэше процессора подвязан к тактовой частоте. Таким образом, к следующему такту, битлинии уже будут иметь валидный уровень напряжения.
Устройство SRAM, а главным образом отсутствие конденсатора делают эту память сильно быстрее. Ведь контроллер теперь не имеет таймингов и логики работы для регенерации заряда. А также, влияет и расположение памяти относительного главного чипа. В случае с процессором, его кэш располагается внутри самих ядер(L1, L2), а L3 на одном кристалле. Что минимизирует задержки по передаче данных. Также из-за различий в схемотехнике, SRAM, являющаяся кэшем процессора и работающая на той же частоте, что и SDRAM, будет греться сильнее. Это происходит из-за того, что компонент SRAM занимает места больше, чем у SDRAM, при этом её плотность в процессорном кэше сильно выше, чем у чипа SDRAM.
Несмотря на то, что SRAM гораздо быстрее DRAM, она тоже имеет задержки, которые относятся к физике проводников, скорости распространения сигнала в них и заложенные в логике контроллера. Такие задержки, обычно короче одного такта. Однако, при повышении частоты, время самого такта, очевидно уменьшается. При больших значениях частот, физические задержки могут уже начать превышать время такта, и в таком случае либо повышается напряжение памяти, либо изменяются тайминги внутри контроллера, чтобы он ожидал данные, например, не на 3 такте, а на 6. К физическим задержкам SRAM добавляется, как было упомянуто ранее, задержки на передачу сигнала, если память расположена на расстоянии от главного чипа, а также задержки логики контроллеров на поиск данных. Хорошим примером накладывания таких задержек, является L3 кэш, обычно кратно больший по своему объёму, что просто усложняет в нём поиск необходимых данных. А так как L3 кэш расположен ещё и отдельно от ядер, то он находится в другом тактовом домене и управляется другим тактовым генератором. По терминологии Intel, место, где располагается этот кэш и некоторые другие компоненты процессора, именуется как uncore(подробнее см. п. 1.3 статьи "Параллельные вычисления в архитектурах процессоров"). Так как uncore работает на другой частоте, то для передачи данных между ядрами и L3 применяются разные механизмы. В рамках этой статьи мы не будем это рассматривать, так как объём текста получится слишком большим. Однако, основной способ передачи данных между разными тактовыми доменами заключается в реализации специального моста, именуемого Асинхронный мост(например Asynchronous FIFO), который синхронизирует такты двух сторон, что тоже накладывает небольшую задержку.
До 2021 года было принято считать, что все эти задержки L3 кэша, являются критическими. Но с разработкой кэша по технологии 3D V-Cache компанией AMD, было технически «доказано», что увеличение кэша и несущественное увеличение задержек из-за этого, всё ещё сильно превосходит случаи доступа к ОЗУ в случае кэш-промахов. Основным принципом данной технологии является наслоение массивов памяти друг на друга, что позволяет сократить маршруты передачи данных, а также, горизонтально экономит место на кристалле. Стоит отметить, что в первых процессорах, где применялась такая технология, была выбрана неудачная компоновка, по которой, кэш располагался между теплораспределительной крышкой и ядрами, что очевидно, ухудшало их охлаждение. По этой причине частоты были заблокированы. Позднее, с выходом архитектуры Zen 5, AMD перенесла кэш под ядра, что сильно улучшило их охлаждение.
2. Работа с памятью
Когда процессору нужно получить данные с определённого адреса в памяти, он сперва проверяет эти данные в кэше, если их там нет(кэш промах, англ. Cache Miss), процессор ищет их в ОЗУ, если и в ОЗУ нет нужных данных, операционная система загрузит страницы памяти из файла подкачки с диска. Всё это создаёт колоссальную задержку. Когда процессор наконец находит данные, он помещает их в кэш, обрабатывает их, далее они могут быть загружены обратно в память, согласно политике замещения данных.
Если же процессор находит данные в кэше(попадание в кэш, англ. Cache Hit), эти данные будут немедленно обработаны.
Процент попаданий и промахов вычисляется так:
Среднее время доступа(англ. Average Memory Access Time, AMAT) - среднее время, которое тратит процессор, ожидая доступа к памяти при выполнении команд загрузки или сохранения данных.
Полученное значение является тактами, либо нс/мс/и пр. – зависит от единиц измерения времени доступа к узлам.
Например, время доступа к кэшу будет равно 4 тактам(процессорным), процент промахов в кэше составляет 30%(что очень много для современных архитектур). Время доступа к ОЗУ составляет 200 тактов, процент промахов в ОЗУ ноль – нужные данные всегда в памяти. Так, получается AMAT = 4 + 0.3 * 200 = 64 такта. Это значит, что на каждую операцию доступа к данным, при этом неважно где они расположены: в кэше или ОЗУ, у процессора в среднем будет уходить 64 такта.
Например, есть такой код:
MOV rax, qword ptr[mem]
loop:
INC rax
JMP loop
Читаем значение по адресу mem, записываем его в регистр rax, инкрементируем значение циклически.
В случае, если по адресу mem произойдёт кэш промах, то конвейер «остановится» на 204 такта на инструкции INC(обработка кэш-промахов детальнее описана в главе 6.2). Сравним на примере архитектуры Haswell, как она бы работала, если бы имела такой большой процент кэш-промахов:
Так, MOV для 64-бит имеет задержку выполнения от 4 до 5 тактов. Для примера будем брать самые худшие/медленные случаи. INC занимает 9 тактов(скорее всего сильно меньше для операнда-регистра, но найти информацию об этом трудно). JMP как правило не занимает время, примем как 0. Однако, JMP влияет на предсказание ветвления. В случаях неудачного расчёта, могут возникнуть задержки, но это совсем другая история. Итого получаем, что сам цикл занимает 9 тактов. Получается, что за время ожидания данных из ОЗУ, процессор мог бы сделать инкремент 204 / 9 = 22 раза. При AMAT = 64, в среднем при каждом обращении к данным, процессор мог бы проходить этот цикл 64 / 9 = 7 раз.
3. Организация кэша
Кэш-память состоит из блоков фиксированной длины – кэш-линий/строк и контроллера. Кэш-линия - это минимальная единица с которой работает кэш. Кэш-контроллер содержит всю логику работы: загрузка и чтение данных в/из кэш-памяти, а также сведение количества кэш-промахов к минимуму и обеспечение актуальности данных.
Как узнать сколько линий содержит кэш:
Сама длина кэш-строки обычно равна от 16 до 64 байт. В современных процессах преимущественно 64 байта, но зависит от конкретной архитектуры процессора.
Например, у i7-4790K L1 кэш имеет суммарный размер 256 Кб. А длина кэш-линии равна 64 байтам.
Чтобы не путать читателя и не усложнять текст названиями, примем, что один килобайт равен 1024 байтам и т.д. То есть 256 Кб = 256 * 1024 байт.
Найдём кол-во кэш-строк:
Основной принцип кэширования, основывается на двух понятиях:
Временная локальность – определяет, что если в настоящий момент потребовались данные по адресу N, то эти данные вскоре снова понадобятся.
Пространственная локальность – определяет, что соседние адреса рядом с N(N + k, где k – длина кэш-линии), вероятно, тоже вскоре понадобятся.
На настоящий момент, политика кэширования в большинстве процессорных архитектур полностью полагается на временную локальность и если запрашиваемые данные отсутствуют в кэше, то они немедленно будут в него добавлены. При этом, программист может использовать механику Non-Temporal Access, оперируя данными, минуя их загрузку в кэш, чтобы избежать его загрязнения информацией, которая потребуется только один раз.
4. Ассоциативность
Ассоциативность показывает, как ОЗУ отображается на кэш память. С увеличением степени ассоциативности, эффективность кэша существенно возрастает.
Как было указано ранее, кэш-линия – это минимальная единица работы с кэш-памятью. Но как именно процессор записывает данные в кэш-линию и потом находит нужную информацию из неё или как как вся ОЗУ отображается на, кратно меньший по размеру кэш?
Если читается один байт, то прочтётся всё слово, выровненное на размер кэш-линии(пространственная локальность), которое захватит с собой определённый диапазон адресов. Поэтому разделим всю ОЗУ на блоки, равные размеру кэш-строки, что позволяет теперь оперировать данными в памяти уже не отдельными байтами, а целой строкой. Так как кэш сильно меньше ОЗУ, то определим так, чтобы несколько одних и тех же блоков из ОЗУ загружались в одинаковую кэш-линию. Это создаёт особую структуру и адресацию по поиску данных самих кэш-линий внутри кэша. Маска адреса, для определения кэш-строки и данных внутри неё:
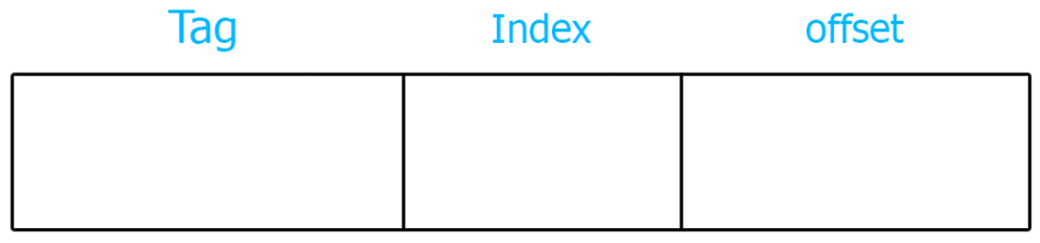
Индекс – содержит номер строки в кэше. Так как в кэше у нас может быть много строк, чтобы не перебирать их по отдельности, благодаря этому полю мы точно знаем, какую кэш-линию надо начать обрабатывать.
Тег - хранит несколько старших бит адреса, т.к. именно старшая часть адреса меняется реже всего, это позволяет точно определить какой блок из ОЗУ загружен сейчас в кэш-линию, в масштабе вообще всего адресного пространства. Кэш-линия имеет поле тег в своей структуре.
Смещение - младшая часть адреса. Используется для извлечения нужных байт из всего массива данных.
Размер смещения: log2N размера кэш-строки.
Размер индекса: log2N, где N - количество строк в кэше.
Размер тега: разрядность адреса - размер индекса - смещение.
Например, используется 64-битный адрес, размер кэш-линии 64 байта, количество строк в кэше равно 4096. Таким образом, размер смещения составит 6 бит(первые младшие биты адреса), что позволяет описать по-байтово 26 = 64 байта – то есть все данные в строке. Размер индекса равен 12 битам. Размер тега равен 64 – 12 – 6 = 46 бит, что очень много и позволяет адресовать аж 70 ТБ. В современных архитектурах, физически шины адреса могут быть чуть меньше, для экономии на схемотехнике, так как такие избыточные размеры диапазонов, часто не нужны.
На примере настоящего 64-битного виртуального адреса(A): 0x7A2B 9C1E 4F8D 3A56, не принимая во внимание трансляцию виртуального адреса в физический.
Смещение имеет значение: A & 0x3F = 22(dec).
Индекс имеет значение: (A & 0x3FFC0) >> 6= 1257 (dec).
Тег имеет значение(TagValue): (A & 0xFFFF FFFF FFFC 0000) >> 18 = 0x1E8A E707 93E3.
То есть, если есть такой код:
mov rax qword ptr[mem],
где mem равен A, то при обращении в кэш это будет выглядеть как: из всех строк в кэше, нужна строка с индексом 1257, её тег должен содержать значение TagValue(тогда это кэш-попадание), из всех 64 байт, нам нужно 8 байт(так как qword ptr) начиная с байта под индексом 22.
Примерный вид кэш-линии, справедливый для кэша с прямым отображением(см. следующий раздел):

Область данных(Data) - непосредственно, сами данные из ОЗУ. В документациях, под термином размер кэш-строки, по умолчанию имеется в виду именно эта область.
Valid bit - бит актуальности данных. Показывает, пуста ли кэш-линия. При включении системы, все кэш-линии хранят ноль в качестве бита валидности. Это поле также может быть и частью Add. data.
Область дополнительных данных(Additional data) - хранит "грязный" бит и/или другую информацию для алгоритмов замещения и когерентности в виде битовой маски.
4.1 Структуры кэш-памяти
Полностью ассоциативный кэш
В таком кэше на каждую кэш-линию могут отобразиться все адреса ОЗУ.
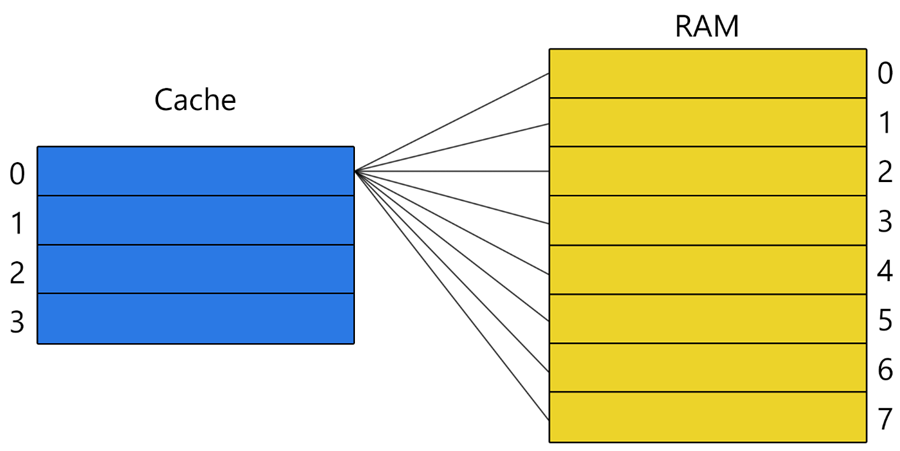
Минус такого кэша заключается в долгом поиске данных, так как для этого надо просмотреть тег каждой строки. И даже если бы за один такт просматривалось по два тега, это всё равно было бы очень медленно. Поэтому полностью ассоциативные кэши, обычно, небольшого размера, что снижает затраты на схемотехнику и уменьшает тепловыделение. К плюсу такого подхода относится тот факт, что в нём нет конкуренции за строку, в отличии от структур, описанных далее. Блок просто займёт пустую строку. В случае, если кэш уже заполнен, то алгоритм замещения разрешит такую ситуацию(см. главу 7).
Кэш с прямым отображением
В этом кэше, каждая строка ОЗУ жёстко закреплена за определённой кэш-линией. А так как кэш меньше ОЗУ, каждая кэш-линия может содержать данные только строго определённых строк из ОЗУ. Для именно такой структуры, и была представлена структура кэш-линии и расчёты в предыдущем разделе.
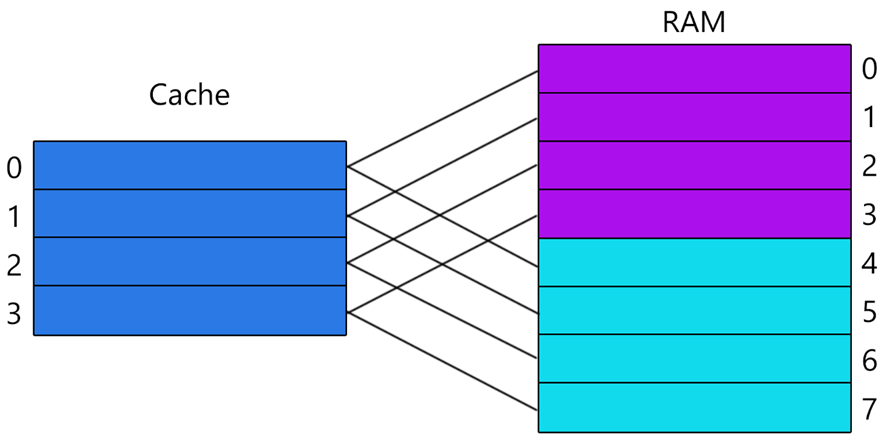
Этот кэш уже не имеет недостатка по скорости нахождения данных, однако есть и существенный недостаток: на одну кэш-линию претендуют несколько строк ОЗУ, а в единицу времени кэш-строка может хранить данные только из одной строки ОЗУ. И когда происходит кэш-промах, данные в кэш-строке перезаписываются. Таким образом, если программа хранит часто используемые данные в тех адресах, которые отображаются на одну кэш-линию, процессор будет постоянно перезаписывать кэш-строку, даже несмотря на то, что другие кэш-линии пустые. Это увеличивает процент кэш-промахов, что существенно снижает производительность.
Узнать, в какую кэш-линию будет загружена информация из ОЗУ можно по формуле:
Наборно ассоциативный кэш
или
N-секционный наборно-ассоциативный кэш (N-way set associative cache)
Этот кэш лишён недостатков двух предыдущих типов. Кэш память делится на наборы. Каждый такой набор имеет прямое отображение на память. Внутри, каждый набор содержит по N кэш-линий, называемых в этой структуре также каналами(англ. N-way cache – N-канальный кэш) и является полностью ассоциативным. Структуры маски адреса и кэш-линии, ранее описанные, подходят и под этот кэш, но с небольшим отличием. Выбрав из адреса индекс, мы точно определяем в каком наборе находится строка. Далее просто перебираем массив из N(обычно небольшого размера) строк и ищем нужный тег из адреса. Количество наборов всегда равно степени 2, а вот количество каналов может строго зависеть от конкретной реализации.
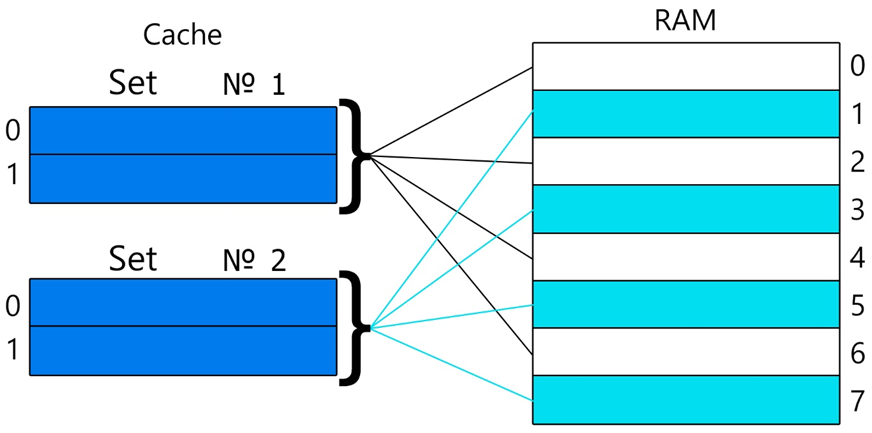
Из-за структуры кэша, изменится размер индекса и тега:
Размер индекса: log2S, где S - кол-во наборов.
Размер тега: разрядность адреса – индекс – 6(смещение всё такое же)
Определить в какой набор попадёт строка из памяти, можно по формуле из кэша прямого отображения, с тем лишь изменением, что теперь учитывается количество наборов в кэше, а не самих строк:
5. Многоуровневая организация кэша
Чем больше объём кэша, тем он медленнее. Из двух вариантов: сделать один большой, но медленный кэш или сделать несколько маленьких, но быстрых - лучше оказывается второй вариант. Так современные процессоры имеют как минимум два уровня кэша. Intel начала использовать три уровня с начала 2000х. AMD же перешла на эту систему только в 2007 с выходом линейки процессоров Phenom.
Кэш первого уровня является самым малым по объёму, но и самым быстрым. Он локален для каждого ядра. В свою очередь поделён на кэш данных - L1D и кэш инструкций - L1I(принцип гарвардской архитектуры процессора). Сделано это для параллельного доступа к кэшу и для чтения, и для записи данных. Так инструкции обычно только читаются, а данные могут модифицироваться. Для такого одновременного доступа необходимо увеличить количество портов доступа у матрицы ячеек кэша, что занимает больше места на кристалле и может вызывать задержки. Поэтому L1 обычно именно физически разделён. Также, такой подход уменьшает загрязнение кэша. Так как объём данных больше, чем объём инструкций, без разделения кэша, они могли бы замещать инструкции и их пришлось вновь подгружать из других уровней кэша/памяти, вставляя простой конвейера. Более того, чтобы минимизировать задержки передачи сигнала – кэш инструкций расположен как можно ближе к блоку выборки/декодирования, а кэш данных расположен ближе к регистровому файлу/исполнительным блокам.
Так как в статье рассматриваются процессоры x86 архитектуры, а это CISC, стоит дополнить, что L1I-кэш содержит/рядом с ним находится небольшой буфер – кэш микроопераций(англ. UOP Cache) уже декодированных инструкций. Иногда этот кэш считается L0. Данный кэш очень полезен в циклах, рекурсиях и прочих повторениях выполнения одного и того же кода. Однажды декодировав инструкцию, при следующей итерации, процессор уже не станет это делать(декодирование инструкций может занимать несколько тактов), а возьмёт уже готовый результат из кэша. Если выполняется код, который чисто последовательный с адреса A по адрес N, то очевидно, UOP тут не поможет и будет всегда хранить ненужную информацию. Однако, такой код занимает меньшую долю кода ПО. Например, это может быть код инициализации программы, или обработчик исключения, который ведёт к завершению программы. Стоит отметить, что UOP кэш довольно маленький и не всегда сохраняет результаты декодирования инструкций, которые представляются большой последовательностью микроопераций, а также обновление данных может быть выполнено по простому LRU(англ. Least Recently Used) принципу.
Кэш второго уровня имеет объём чуть больше чем кэш первого уровня, из-за этого медленнее. Тоже локален для каждого ядра. Уже не разделён на части, но также хранит данные и инструкции, но обращение к ним происходит реже, чем к данным и инструкциям из L1 кэша.
Кэш третьего уровня самый большой по объёму и в то же время самый медленный из всех уровней. Является общим для всех ядер. Также хранит, как и данные, так и инструкции и может рассматриваться как общий буфер между ядрами. Согласно политике когерентности(см. главу 8), L3 хранит информацию о том, какие данные находятся в L1-L2 кэшах каждого ядра. Существует три основных вида организации этого кэша(L1-L2 тоже могут иметь подобные типы):
· Инклюзивный – предписывает L3 хранить точные копии всех L1-L2 кэшей и иметь специальные поля и битовые маски у кэш-линии: в каких ядрах и под какими флагами она находится – то есть реализация протоколов когерентности, Snoop Filter или аналога(см. главу 8). Если данных по адресу нет в L3 – значит их нет ни в одном другом кэше ни у одного из ядер. Очевидный минус – нерациональное использование объёма кэша. Так, если суммарный объём L1-L2 равен 2 Мб, размер L3 равен 8 МБ. То для уникальных данных остаётся 6 МБ. Применялись Intel c поколения Nehalem по Kaby Lake.
· Эксклюзивный – не содержит обязательных копий из других кэшей, но реализовывают Snoop Filter или аналог для осуществления когерентности. В основном применились AMD в поколениях K8 и Zen.
· Non-Inclusive Non-Exclusive (NINE), который не предписывает строго хранить/не хранить копии данных из других кэшей. В случае с инклюзивным кэшем, данные, которые вытесняются из L3, должны быть вытеснены и из других кэшей, даже если они используются ядром. Что вызывает кэш-промахи очевидно. В NINE нужные данные могут остаться в других кэшах, но удалены из L3. Или наоборот сброшены именно в L3, для освобождения L1, L2(так называемый Victim cache). Применяется Intel c поколения Rocket Lake по настоящий момент(Март 2026).
Применительно к микроархитектуре, основанной на чиплетах, L3 расположен локально для каждого чиплета, содержащего ядра(CCD). Поэтому, на передачу данных между ядрами с разных чиплетов накладываются дополнительные задержки, которых нет в монолитных процессорах.
Стоит отметить, что, начиная с поколения Sandy Bridge, Intel стала разделять L3-кэш на несколько отдельных блоков, количество которых, обычно равно количеству ядер. Это увеличило пропускную способность, ведь одновременно можно записывать в разные блоки памяти. С каждым ядром, физически рядом располагается блок L3-кэша, что снижает задержки по передаче данных по шине. Размер одного блока меньше – это упрощает поиск данных. Также, контроллер кэша CBo(англ. Caching Box) идёт свой для каждого блока памяти, что уменьшает его элементную базу из-за размера кэша. Ему надо описать условно 2 МБ, а не 8 МБ – что просто дешевле в производстве.
Итоговая схема:

Примечание: Схема является упрощённой, так в действительности кольцевая шина имеет несколько колец: для данных, запросов и т.д.
6. Стратегия кэширования
Когда процессор записывает данные в кэш-линию, в неё попадают байты не только находящиеся по текущему адресу, но также и из соседних адресов. Так как кэш-строка фиксированного размера - реализована пространственная локальность.
Физически поиск запрашиваемых данных может осуществляться двумя способами: Look Through, Look Aside.
Реализация Look Through(и комбинации с ней) используется в современных процессорах и основана на том, что запрашиваемые данные сперва ищутся в кэше, если их там нет, то контроллер кэша сам отправляет запрос в контроллер памяти, который уже ищет информацию в ОЗУ.
В случае Look Aside, при запросе данных, оба контроллера получают эту команду. Если происходит попадание в кэш, то запрос в ОЗУ прекращается – контроллер кэша пошлёт контроллеру памяти по шине команду. Иначе поиск данных продолжается в основной памяти. При такой стратегии увеличивается энергопотребление из-за нагрузки на систему, но сокращается время доступа к памяти в случае кэш-промаха. Применялись в системах с 80-90х годов, вплоть до первых Pentium. И в тех системах, кэш и кэш-контроллеры были частью чипсета материнской платы.
В обоих случаях, если данные были выгружены в файл подкачки, процесс поиска сильно увеличивается, так как ОС должна будет сперва эти данные разместить в памяти.
6.1 Предварительная загрузка
Загрузка данных в кэш основывается на некоторых механизмах и стратегиях, основными задачами которых, является загрузка именно полезных данных и минимизация загрязнениях кэша лишней информацией. Поэтому контроллер должен как-то предполагать, какие данные вскоре будут нужны и использует для этого механизм предвыборки(англ. Prefetching). Самая простая стратегия заключается в том, что запись в кэш происходит в тот момент, когда кэш-контроллер не обнаружил нужных данных. То есть происходит загрузка по требованию.
Более продвинутая стратегия - упреждающая загрузка данных. Предполагается, что данные из ОЗУ обрабатываются в порядке возрастания адресов. Здесь как раз используется пространственная локальность. Однако этот механизм тоже имеет недостаток, т.к. не всегда данные в программе могут обрабатываться по порядку из-за ветвлений кода и неоднородных структур данных.
Упреждающая спекулятивная загрузка/ Аппаратная предварительная выборка (англ. Hardware Prefetching) - алгоритмы, которые предсказывают адрес следующего блока памяти на основе прошлых обращений, их шаблонов. Именно такие алгоритмы используются в современных процессорах. В BIOS некоторых материнских плат присутствует отдельный параметр, позволяющий включить/отключить этот механизм у процессора. Аппаратный префетчер называется так, потому что реализован на основе нескольких физических блоков внутри процессора. Сами блоки могут быть отдельными реализациями тех или иных стратегий предсказаний:
Stream Prefetcher – линейный, для предсказаний при последовательной работе с памятью, например, использования массивов. При этом он эффективно справляется с работой с памятью в обоих направлениях. Например, в циклах с инкрементом или декрементом. Когда алгоритм распознает последовательный паттерн обращений, он начинает сам запрашивать N кэш-линий(обычно 64 байта) из памяти по последовательным адресам: A+1, A+2, … N зависит от конкретной реализации механизма и называется степенью упреждения(англ. Prefetch Degree). То есть сколько кэш-линий будет заполняться за такой запрос. Очевидно, что большое значение неэффективно, так как велика вероятность, что эти данные не будут нужны, а шина памяти будет загружена ими. Существует и дистанция упреждения(англ. Prefetch Distance), которая описывает, насколько далеко(по времени или кол-ву кэш-линий) алгоритм будет смотреть при выборке данных. Это необходимо из-за учёта задержек памяти, так как данные должны быть в кэше к тому моменту, когда они потребуются процессору.
Stride Prefetcher – предугадывает блок памяти, когда работа с ней происходит через интервалы, например, из массива объектов класса выбирается только конкретное поле:
Person collection[5] = {…};
for(uint i = 0; i < 5; ++i)
{
collection[i].id = i;
}
Стоит отметить, что данный код может обработать и линейный префетчер, однако только тогда, когда размер структуры Person меньше самой кэш-линии(обычно 64 байта). Если же он больше, то в кэш-линии A + 1 произойдёт кэш-промах. Stride Prefetcher в этом случае окажется сильно эффективнее и сможет загружать кэш-линии, в которых будет уже нужный адрес.
Data Memory-dependent Prefetcher или Data Dependent Prefetcher у Intel – предсказывает блоки памяти на основе истории адресов. Используется, когда доступ к памяти происходит нелинейно или по более сложным шаблонам, например, связные списки.
В более новых процессорах также используются аппаратные предсказатели на основе нейронных сетей, например, Perceptron-based prefetcher, который основан на нейронной сети типа Перцептрон. Основным их преимуществом является точность предсказаний и как следствие – сильное снижение загрязнения кэша. Само использование перцепторна и вообще элементов нейронных сетей, началось ещё в первой половине 2010х, например, в архитектуре Piledriver у AMD в алгоритмах предсказателя ветвлений.
В дополнение к стратегиям кэширования, во многих процессорах реализован механизм Adjacent Cache Line Prefetch. Суть которого очень проста – он всегда догружает в кэш соседнюю кэш-линию вместе с запрошенной и обычно работает с любыми стратегиями предвыборки данных. Это может выглядеть, что процессор имеет кэш-линию в 128 байт. Но в высоконагруженных вычислениях этот механизм может снижать производительность, просто забивая шину памяти ненужными данным.
Для более детального ознакомления с предвыборкой данных, рекомендую презентацию Memory Prefetching by Nima Honarmand.
6.2 Обработка кэш-промахов
Загрузка в кэш происходит не только на основе предсказаний, но и в момент кэш-промахов. Ведь описанные ранее стратегии, не устраняют промахи, а лишь стараются свести их количество к минимуму. Обработка кэш-промахов является неблокирующей, что позволяет конвейеру выполнять другие инструкции, не зависящие от ожидаемых данных.
Когда происходит кэш-промах, то информация(адрес, данные кэш-строки и пр.) об этом записывается в MSHR (англ. Miss Status Holding Registers) – отдельный регистровый файл внутри контроллера кэша(каждого уровня, со своими внутренними особенностями). MSHR позволяет отсрочить «остановку» конвейера на свою длину. То есть, если размер MSHR 10 записей, то без зависимости по данным в инструкциях кода, конвейер «остановится», когда произойдёт 11 кэш-промах подряд, по разным кэш-строкам и MSHR не сможет вместить эту запись в себя. Сам же MSHR также используется для оптимизации запросов: так если несколько раз произошёл кэш-промах по одной кэш-строке, то контроллер это объединит в один запрос к памяти. Однако, если происходит кэш-промах на инструкции, и её результат выполнения необходим для следующих – возникает зависимость по данным и конвейер будет условно «остановлен»(не станем вдаваться в подробности устройства самого конвейера). Когда запрос на кэш-промах удовлетворяется, то MSHR оповещает об этом исполнительный блок ядра и инструкция, по которой был кэш-промах, помечается как готовая к выполнению.
Как было указано ранее, MSHR находится в кэш-контроллерах каждого уровня и имеет свои внутренние различия по устройству и работе. Это значит, что когда L1 запрашивает из L2, а L2 из L3, то запрос проходит через локальные MSHR и если в одном из них не хватает места, то запрос блокируется и ожидается. Так, если MSHR у L3 заполнен, то запрос к этому кэшу блокируется, место в MSHR у L2 тоже не освобождается, что уже может вызвать остановку запросов к нему, тем временем в MSHR L1 место тоже заканчивается и это вызывает условную «остановку» конвейера. Стоит отметить, что MSHR используется только при регистрации промаха. Если MSHR у L3 занят, но контроллер регистрирует попадание, то данные будут возвращены L2 и MSHR у L3 в этом процессе не участвует.
7. Политики замещения данных
Кэш не просто имеет малый размер по сравнению с обычной ОЗУ, но и большую часть работы всегда заполнен данными. Поэтому существует несколько политик замещения, которые позволяют загружать новые данные, не перезаписывая при этом нужные. Некоторые из них:
1) LRU (Least Recently Used)/ PLRU - замещаются данные, которые дольше всего не использовались. Для того, чтобы отслеживать как часто используется строка, могут использоваться обычно матрицы или индексы в списке. Для списка, индекс имеет размер log2(количество кэш-строк) бит и хранит по сути индексы самих строк. Так при обращении к строке, её индекс будет перенесён в начало списка, все индексы, что были до неё, сдвинутся вправо. Индексы, что были после – не изменятся. При поиске строки на удаление, алгоритм возьмёт строку, чей индекс находится последним в списке.
Так, например, список имеет вид: 0, 1, 2, 3. Происходит обращение к строке 2. Теперь список: 2, 0, 1, 3. Обращение к строке 3 меняет список: 3, 2, 0, 1. Теперь, если необходимо вытеснить строку, то выбирается самая последняя – строка 1. И после добавления новой, список имеет вид: N, 3, 2, 0.
Данный подход очень сложен и громоздок в плане реализации логики. Поэтому, часто используется матрица доступа. В которой строки и столбцы соответствуют индексу линии. При обращении к кэш-линии, строка в матрице с её индексом заполняется 1, столбец же обнуляется. При поиске строки на вытеснение, алгоритм проверяет, какая строка матрицы имеет наименьшую сумму.
Так, например, если произошло обращение к кэш-линии 1:
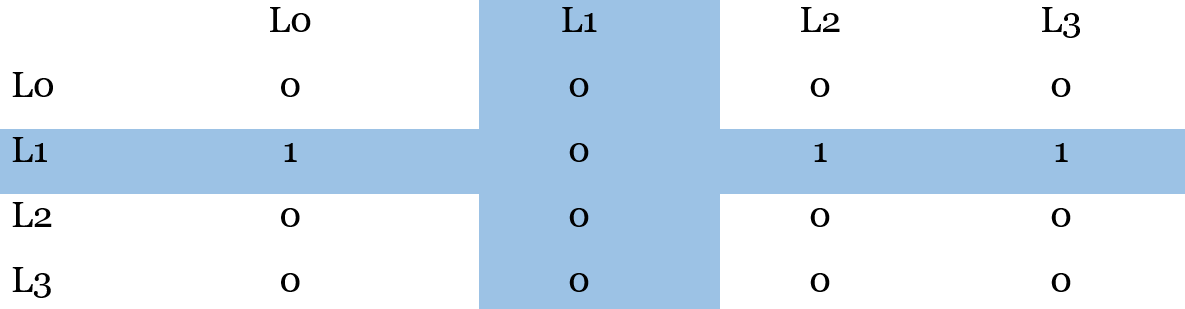
Обращение к кэш-линии 3:
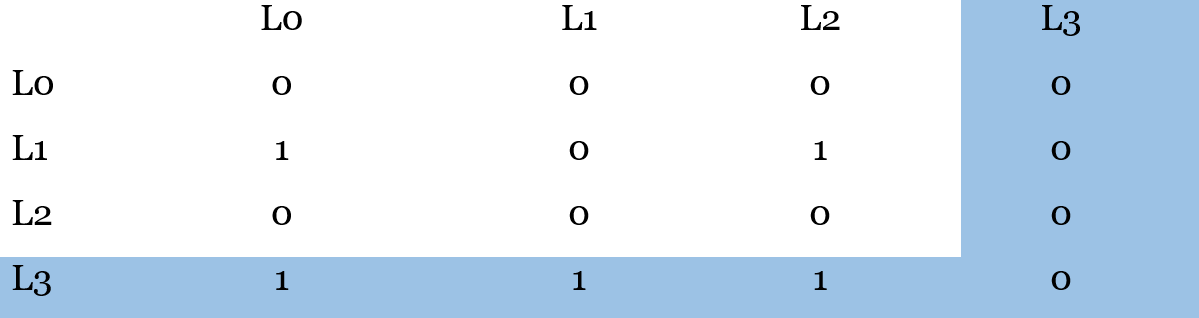
При поиске строки на вытеснение, L0 и L2 кандидаты, затем идёт L1 и так как L3 самая новая – она в конце.
Так, для 4-way кэша в примерах выше потребуется 8 бит в случае использования списка. Для матрицы потребуется 16 бит, но обычно используется различного рода оптимизации, позволяющие снизить потребление памяти примерно в два раза. Так или иначе, сама логика такого алгоритма выходит сложной в схемотехнике: одно обращение к одной строке заставляет переключать сразу массу бит плюс и логика выбора, что вызывает задержки и простое потребление энергии. Поэтому такой алгоритм если и используется, то в кэшах с очень малым размером.
Вместо LRU часто применяется Pseudo-LRU, который использует битовые деревья. Например, есть 4 строки - корень дерева разделит их условно на две группы. Если корень имеет значение 0, переходим в узел A, иначе в B. Значение бита в узле A будет указывать на строку, которую стоит вытеснить. На 8-канальный кэш требуется в таком случае всего 7 бит. Недостатком этого дерева является то, что в отличии от LRU, PLRU не всегда вытеснит самую старую кэш-линию, так как существуют одинаковые состояния дерева, для обращений к разным строкам. В обычном LRU всегда точно хранится история обращений. Стоит отметить, что оба алгоритма примерно одинаковы в своей точности, но PLRU проще в реализации и быстрее.
2) NRU(англ. Not Recently Used)/ Bit-PLRU – очень эффективный алгоритм с точки зрения реализации и производительности. Однако не знает историю обращений. Заключается в том, что кэш-линия хранит всего лишь один бит для него. Когда строка используется, этот бит устанавливается в 1, что означает, что данные используются. При поиске строки на вытеснение, алгоритм ищет первую строку, у которой этот бит будет равен 0. Если все строки имеют бит равным 1, то алгоритм сбрасывает массово это значение и начинает цикл поиска заново. Если с момента сброса флага и до момента проверки алгоритмом, к кэш-строке не будет обращения и она окажется такой первой в списке алгоритма – она будет выгружена. В зависимости от реализации, делать сброс битов можно и при установке бита.
3) RRIP (англ. Re-Reference Interval Prediction) – алгоритм разработан Intel в 2010 году на смену LRU. Часто используется в L3-кэшах и оказывается очень эффективен при работе с потоковыми данными, которые обычно засоряют кэш и не используются повторно. Для него кэш-строка содержит два бита(имеет название RRPV, англ. Re-Reference Prediction Value) и использует значения [0; 3], которое означает как скоро данные могут понадобиться.
Так, значение 0 означает, что данные только что использовались и возможно скоро снова понадобятся. Значения 1-2 означают среднесрочную перспективу на использование. Значение же 3 означает, что данные использовались давно, и возможно будут использоваться не скоро или вообще никогда. Стоит отметить, что для эффективного контроля новых данных, в особенности быстрого вытеснения потоковых данных, когда они записываются в кэш-линию, то есть происходит кэш-промах, то такой линии присваивается значение 2 – это вариация алгоритма Static RRIP. Существует второй вариант реализации - Bimodal RRIP: с небольшой вероятностью, записываемым данным присвоится значение 3 – попытка быстрее вытеснить данные. Начиная с поколения Sandy Bridge применяется вариант алгоритма DRRIP (англ. Dynamic RRIP) – динамически выбирает между SRRIP и BRRIP.
При поиске строки на вытеснение, алгоритм выберет ту строку, у которой значение равно 3. Если ни одной не будет найдено, алгоритм массово инкрементирует значение на разницу между значением 3 и самым большим найденным значением. Обычно такой инкремент предсказуем, потому, повторного поиска может не быть, ведь максимальный элемент уже найден и его значение после инкремента известно.
Подробнее ознакомиться с этим алгоритмом можно в официальной статье Intel, High-Performance Cache Replacement Using Re-Reference Interval Prediction (RRIP), представленной на ISCA 2010.
8. Когерентность
Когерентность – это политика, обеспечивающая актуальность данных в кэше и оперативной памяти и между кэшами разных ядер, между процессорами в многопроцессорных системах. Проблема заключается в том, что ОЗУ доступна как на чтение, так и на запись, что ставит вопрос об отслеживании изменений. К ОЗУ может обратиться периферийное устройство, в многопроцессорных системах - разные процессоры, в многоядерных процессорах – разные ядра. Например, устройство обратилось к ОЗУ, несколькими операциями ранее процессор изменил данные по этому адресу и сохранил у их себя в кэше, сделав тем самым данные в ОЗУ неактуальными. В таком случае устройство получит неверную информацию.
Есть несколько вариантов обеспечения записи данных в основную память:
1) Алгоритм сквозной записи(англ. Write Through) – при записи данных в кэш-строку, они отправляются и в оперативную память. Это делает любую операцию записи медленной и требует пропускной способности от ОЗУ.
2) Алгоритм обратной записи(англ. Write Back) – при записи данных в кэш-строку, они остаются в ней пока строка не будет вытеснена из кэша и/или потребуется явная синхронизация с памятью. При использовании данного алгоритма каждая кэш-строка хранит бит модификации или "грязный"(от англ. dirty) бит. Если данные в кэш-линии изменились - dirty bit = 1, иначе 0.
Существует множество протоколов для когерентности кэша с обратной записью:
· Протокол MESI - один из самых известных. По ссылке можно найти его подробное описание и принцип работы. Intel использует его модификацию – протокол MESIF.
· Протокол MOESI – AMD применяет его в линейке процессоров Ryzen.
· AMBA, ACE, CHI – используются у ARM.
Рассмотрим реализации архитектур на MESI и MESIF. Сами протоколы определяют состояния кэш-линий. Но для их функционирования необходим сам механизм когерентности. В эпоху MESI, как правильно не было инклюзивного L3 кэша и в большинстве случаев самого L3. Однако в некоторых серверных процессорах такая иерархия всё же существовала, но L3 не был полностью инклюзивным и больше работал как кэш жертв. Вместе с MESI применялся механизм прослушивания шины(англ. Bus Snooping). Контроллер каждого кэша прослушивает системную шину на запросы от разных ядер на чтение/запись тех или иных данных, и отправляет, инвалидирует у себя при необходимости данные. Если несколько кэшей содержат данные в одинаковом состоянии(S), то должна применяться сложная логика арбитража шины и выбора какой из кэшей ответит, либо же будет отвечать ОЗУ. Всё это создаёт серьёзные задержки и простои конвейера ядра. Поэтому, Intel была разработана модификация протокола, именуемая MESIF. Которая добавила пятое состояние для кэш-строк. Теперь ответить должен был только тот кэш, у которого данные находятся под флагом F.
|
M Modified Модифицированный |
Строка кэша содержит самые актуальные данные, которые еще не записаны в основную память. Ядро ответственно за обновление памяти при вытеснении строки. |
|
E Exclusive Эксклюзивный |
Данные идентичны основной памяти и присутствуют только в одном кэше. Переход в состояние M происходит мгновенно без уведомления других ядер. |
|
S Shared Разделяемый |
Данные идентичны основной памяти и могут присутствовать в нескольких кэшах. В отличие от MESI, в этом состоянии кэш не имеет права отвечать на запросы других ядер. |
|
I Invalid Недействительный |
Строка считается неактуальной. |
|
F Forward Пересылающий |
Специальная форма состояния Shared. Именно это ядро обязано ответить на запрос другого и отправить данные. |
После выхода MESIF в поколении Nehalem(начало линейки Intel Core), Intel сделала L3 кэш инклюзивным и добавило в него Snoop-каталоги как часть структуры кэш-строки в L3, а также отказавшись от стандартного прослушивания шины, локализовав это. Теперь, в этом кэше дублировались все данные из всех кэшей ядер, а кэш-строки имели специальную маску, указывающие в каком ядре находятся эти данные, так называемые биты присутствия(англ. Presence Bits), Если строки нет в L3 – значит её нет вообще в кэше процессора. В высокопроизводительных процессорах серий Core-X и пр., Intel сделала L3 кэш не инклюзивным и заменила каталоги, на действительно отдельную структуру – Snoop-фильтр.
После Nehalem, в поколении Sandy Bridge была введена кольцевая шина, для которой идеально подошёл MESIF. В современных системах, за когерентность кэша обычно отвечает контроллер L3 кэша – CBo(см. рисунок 9). Однако, для осуществления когерентности данных согласованно работают сразу несколько блоков. Так, на кольцевой шине, вместе с ядрами и L3 кэшем находится системный агент(англ. System Agent), содержащий в себе некоторые контроллеры. Одними из таких являются IOMMU(англ. Input-Output Memory Management Unit) – отвечает за трансляцию адресов и безопасность DMA(англ. Direct Memory Access) запросов, SAD (англ. System Address Decoder) – определяет, куда направляется запрос(на кольцо, в ОЗУ и т.д.).
Рассмотрим, как осуществляется когерентность кэша по протоколу MESIF с инклюзивным L3, если в системе находится DMA-устройство, которое запрашивает доступ к памяти на чтение/запись:
Механизм когерентности обязывает SAD помечать любой запрос к памяти как «когерентный» и отправить его на кольцевую шину. Далее, контроллер CBo, чей диапазон адресов содержит указанный адрес в запросе, перехватывает такой сигнал и проверяет, содержит ли его кэш действительно данные по адресу из запроса. Если таковые имеются в самом L3 если он инклюзивен, либо в структуре Snoop Filters в этом же кэше, если он не инклюзивен, то CBo отправляет запрос на конкретное ядро к конкретному контроллеру L1/L2 кэша, где строка помечена флагом F, либо выдаёт DMA-устройству копию из самого L3 кэша.
Если же DMA-устройство изменяет данные, то CBo согласно MESIF, рассылает всем кэшам, которые содержат копию этой кэш-строки, запрос на инвалидацию данных, что пытается изменить DMA, дожидается от них ответа и лишь потом отправляет запрос контроллеру памяти, на запись данных от DMA в ОЗУ. В серверных процессорах, Intel вместе с отличиями архитектур, применяет технологию Data Direct I/O для прямой записи данных в кэш.
Примечание: Пакет данных на шине PCI-E(а именно к ней обычно подключены DMA-устройства) обычно имеет атрибут No Snoop, который может быть установлен. В системах с аппаратной когерентностью, как например в x86, скорее всего, это будет проигнорировано.
В случае же когерентности между ядрами, основной принцип также строится на обмене сообщениями на кольцевой шине между ядрами и L3 кэшем. Так как Intel не публикуют реализации своих архитектур, дальнейший разбор является чисто академическим, с небольшим взглядом на особенности реализации аппаратуры. Для рассмотрения когерентности возьмём протокол MESIF.
Примечание: Фактическая передача флагов между кэш-линиями сильно зависит от той или иной реализации. Физические реализации, далее описанных логик, могут сильно различаться.
Учитывая, что все запросы на когерентность идут всегда сначала через CBo, то если ядро 1 имеет кэш-промах, оно сперва обратиться в CBo(согласно адресу памяти), который увидит, что запрашиваемая кэш-линия имеет:
1. флаг M: согласно протоколу, только одно ядро является владельцем. И оно недавно изменило данные. Более того, на этот момент, физически эти данные могут различаться между локальным кэшем и копией в L3. Попасть в L3 физически они могут либо, когда строка с текущим M флагом будет вытеснена из локального кэша ядра, либо, когда CBo обратиться к контроллеру кэша этого ядра, и запросит данные. Они могут быть записаны в L3, а затем переданы ядру 1. Данные, также могут быть отправлены в основную память, но и это тоже зависит от конкретной реализации. Так, можно откладывать запись в ОЗУ, пока строка не будет вытеснена из L3. В конце, старое ядро-владелец поставит флаг S на такую кэш-линию, а ядро 1 флаг F.
Примечание: Как было упомянуто ранее, изменение флагов зависит от той или иной реализации. Так, после вывода строки из состояния M, текущий владелец может иметь флаг F, а ядро 1 флаг S. Так как нет причин передавать F-флаг ядру 1, а на смену флагов требуется энергия и время.
2. флаг F: при запросе на чтение, CBo направит запрос ядру, у которого флаг кэш-линии установлен в F. Продолжая пример из пункта 1, запрос поступит к ядру 1, оно отправит данные, а у себя установит флаг S. Новый же владелец установит флаг F в своём кэше. Об этом будет знать L3. Однако, CBo вправе переслать копию и из L3-кэша. Флаг F тоже будет перемещён в этом случае, согласно MESIF. Так, не в каждой реализации, в такой ситуации, запрос кэш-строки из L3 будет медленнее передачи между ядрами по кольцевой шине: блок L3 может оказаться рядом с запросившем ядром, нежели ядро с флагом F. Это говорит о том, что MESIF был в основном реализован для систем с общей памятью и шинами и просто перешёл в потребительский сегмент. При этом привнёс и свои плюсы: обычно прямая передача данных от ядра к ядру, может быть и быстрее получения их из L3. Таким образом MESIF позволяет иметь больше контроля.
3. флаг S: в протоколе MESIF, не гарантируется, что при наличии флага S у любого ядра, обязательно найдётся ядро с флагом F(назовём его форвардом) для искомой кэш-линии. Это может произойти, когда ядро-форвард вытесняет такую кэш-строку из своего локального кэша. Получается ситуация как в MESI протоколе, когда несколько ядер имеют одну и ту же строку с флагом S. Но имея инклюзивный L3-кэш, которого не было при MESI, возможно отправить данные сразу из L3, минуя сложный арбитраж шины и тем более запрос в ОЗУ. При этом, запросившее ядро установит флаг F для этой кэш-строки, что вернёт форварда. При этом стоит учитывать, что у Intel применяется механизм Silent Eviction, при котором, если в локальном кэше ядра, у строки на вытеснение установлен флаг S, F или E, то ядро может удалить эти данные из локального кэша, не уведомляя об этом CBo. Таким образом, биты присутствия для этой строки в L3 будут не валидны. Но так как при всех трёх флагах, копии валидны и в локальном кэше, и в L3, даже если строка была тихо вытеснена ядром, L3 может сам ответить на запрос и переслать из себя данные. Биты присутствия будут валидированы при штатном запросе когерентности и их неверное состояние обычно не считается ошибкой, а Silent Eviction экономит трафик внутренней шины. Так как L1 слишком часто может вытеснять данные, то наличие обращения к CBo при каждом вытеснении, сильно нагрузило бы шину.
Если ядро 1 собирается данные модифицировать(не с флагом E), то соответствующий CBo запросит инвалидацию данных у всех ядер(флаг I), у которых есть такая кэш-строка, дождётся подтверждения от каждого, укажет в L3 флаг M для этой строки и передаст право владением кэш-линией ядру 1. Но так как сброса копии из локального кэша в L3 может не произойти при модификации данных(см п. 1), то при любом следующем доступе к этой строке, логика контроллера учтёт флаг вместе с битами присутствия и направит запрос сразу в нужное ядро за актуальными данными.
Примечание: Данное описание логики корректно в рамках процессоров именно с кольцевой шиной. У процессоров AMD на чиплетной архитектуре алгоритм схож, но немного отличается из-за деталей реализации архитектур процессоров.
Заключение
Сохраняющийся на настоящий момент серьёзный технологический разрыв в скорости между процессорами и оперативной памятью, делает её узким местом в вычислениях. И несмотря на сложности реализации кэш-памяти – она является ключевым фактором, позволяющим процессорам обрабатывать данные с минимальными задержками, раскрывая свою производительность, сглаживая недостатки оперативной памяти. На текущий момент(Март 2026), индустрия активно переходит на всё большее количество ядер в процессорах для повышения производительности в многопоточных сценариях, что как и усложняет алгоритмы когерентности, структуры кэш-памяти, так и способствует модернизации кэшей, путём увеличения их объёмов(например AMD 3D V-Cache).
Для системного программиста, понимание работы процессорного кэша является знанием, которое можно эффективно применять на практике, стараясь оптимизировать код на меньшее количество кэш-промахов, повышая производительность ПО.
Конец.
Источники
Текст, схемы, диаграммы, оформление и превью(i5 4460): AmeliePick.